kubernetes(二)安装elk filebeat日志收集系统
0.架构filebeat => kafka_cluster => logatash => elasticsearch_cluster =>kibanafilebeat 以demoset运行在kubernetes集群中的每台宿主机上去收集日志,以kafka集群做消息队列, logstash做日志过滤,存储在elasticsearch集群中,最后由kibana展示。在Ku...
0.架构
filebeat => kafka_cluster => logatash => elasticsearch_cluster =>kibana
filebeat 以demoset运行在kubernetes集群中的每台宿主机上去收集日志,以kafka集群做消息队列, logstash做日志过滤,存储在elasticsearch集群中,最后由kibana展示。
在Kubernetes上部署Elasticsearch集群
1.修改镜像
之所以修改镜像,是因为在k8s中不能直接修改系统参数(ulimit)。官网上的事例是在docker上部署的,docker可以通过ulimits来修改用户资源限制。但是k8s上各种尝试各种碰壁,老外也有不少争论
- 编写Dockerfile,修改镜像
Dockerfile
FROM docker.elastic.co/elasticsearch/elasticsearch:6.2.2
MAINTAINER chenlei leichen.china@gmail.com
COPY run.sh /
RUN chmod 775 /run.sh
CMD ["/run.sh"]
#!/bin/bash
# 设置memlock无限制
ulimit -l unlimited
exec su elasticsearch /usr/local/bin/docker-entrypoint.sh
构建镜像
docker build --tag hub.cap.len.com/elasticsearch/elasticsearch:6.2.2 .
通过上述方式,将镜像的入口命令修改为我们自己的run.sh,然后在脚本内设置memlock,最后调用原本的启动脚本来达到目的。
2.ES集群规划
Elasticsearch我选用的6.2.2的最新版本,集群节点分饰三种角色:master、data、ingest,每个节点担任至少一种角色。每个觉得均有对应的参数指定,下文将描述。
标注为master的节点表示master候选节点,具备成为master的资格,实际的master节点在运行时由其他节点投票产生,集群健康的情况下,同一时刻只有一个master节点,否则称之为脑裂,会导致数据不一致。
| ES节点(POD) | 是否Master | 是否Data | 是否Ingest |
|---|---|---|---|
| 节点1 | Y | N | N |
| 节点2 | Y | N | N |
| 节点3 | Y | N | N |
| 节点4 | N | Y | Y |
| 节点5 | N | Y | Y |
3.编写YML文件并部署集群
---
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
app: elasticsearch
name: elasticsearch-admin
namespace: logging
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: elasticsearch-admin
labels:
app: elasticsearch
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: elasticsearch-admin
namespace: logging
---
kind: Deployment
apiVersion: apps/v1
metadata:
labels:
app: elasticsearch
role: master
name: elasticsearch-master
namespace: logging
spec:
replicas: 3
revisionHistoryLimit: 10
selector:
matchLabels:
app: elasticsearch
role: master
template:
metadata:
labels:
app: elasticsearch
role: master
spec:
serviceAccountName: elasticsearch-admin
containers:
- name: elasticsearch-master
image: hub.cap.len.com/elasticsearch:6.2.2
command: ["bash", "-c", "ulimit -l unlimited && sysctl -w vm.max_map_count=262144 && exec su elasticsearch docker-entrypoint.sh"]
ports:
- containerPort: 9200
protocol: TCP
- containerPort: 9300
protocol: TCP
env:
- name: "cluster.name"
value: "elasticsearch-cluster"
- name: "bootstrap.memory_lock"
value: "true"
- name: "discovery.zen.ping.unicast.hosts"
value: "elasticsearch-discovery"
- name: "discovery.zen.minimum_master_nodes"
value: "2"
- name: "discovery.zen.ping_timeout"
value: "5s"
- name: "node.master"
value: "true"
- name: "node.data"
value: "false"
- name: "node.ingest"
value: "false"
- name: "ES_JAVA_OPTS"
value: "-Xms512m -Xmx512m"
securityContext:
privileged: true
---
kind: Service
apiVersion: v1
metadata:
labels:
app: elasticsearch
name: elasticsearch-discovery
namespace: logging
spec:
ports:
- port: 9300
targetPort: 9300
selector:
app: elasticsearch
role: master
---
apiVersion: v1
kind: Service
metadata:
name: elasticsearch-data-service
namespace: logging
labels:
app: elasticsearch
role: data
spec:
ports:
- port: 9200
name: outer
- port: 9300
name: inner
clusterIP: None
selector:
app: elasticsearch
role: data
---
kind: StatefulSet
apiVersion: apps/v1
metadata:
labels:
app: elasticsearch
role: data
name: elasticsearch-data
namespace: logging
spec:
replicas: 2
revisionHistoryLimit: 10
selector:
matchLabels:
app: elasticsearch
serviceName: elasticsearch-data-service
template:
metadata:
labels:
app: elasticsearch
role: data
spec:
serviceAccountName: elasticsearch-admin
containers:
- name: elasticsearch-data
image: hub.cap.len.com/elasticsearch:6.2.2
command: ["bash", "-c", "ulimit -l unlimited && sysctl -w vm.max_map_count=262144 && chown -R elasticsearch:elasticsearch /usr/share/elasticsearch/data && exec su elasticsearch docker-entrypoint.sh"]
ports:
- containerPort: 9200
protocol: TCP
- containerPort: 9300
protocol: TCP
env:
- name: "cluster.name"
value: "elasticsearch-cluster"
- name: "bootstrap.memory_lock"
value: "true"
- name: "discovery.zen.ping.unicast.hosts"
value: "elasticsearch-discovery"
- name: "node.master"
value: "false"
- name: "node.data"
value: "true"
- name: "ES_JAVA_OPTS"
value: "-Xms1024m -Xmx1024m"
volumeMounts:
- name: elasticsearch-data-volume
mountPath: /usr/share/elasticsearch/data
securityContext:
privileged: true
securityContext:
fsGroup: 1000
volumes:
- name: elasticsearch-data-volume
emptyDir: {}
#volumeClaimTemplates:
# - metadata:
# name: elasticsearch-data-volume
# spec:
# accessModes: ["ReadWriteOnce"]
# storageClassName: "vsphere-volume-sc"
# resources:
# requests:
# storage: 15Gi
---
kind: Service
apiVersion: v1
metadata:
labels:
app: elasticsearch
name: elasticsearch-service
namespace: logging
spec:
ports:
- port: 9200
targetPort: 9200
selector:
app: elasticsearch
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
labels:
app: elasticsearch
name: elasticsearch-ingress
namespace: logging
spec:
rules:
- host: elasticsearch.kube.com
http:
paths:
- backend:
serviceName: elasticsearch-service
servicePort: 9200
通过环境变量设置:node.master、node.data和node.ingest来控制对应的角色,三个选项的默认值均是true;
通过postStart来设置系统内核参数,但是对memlock无效;网上也有通过initPod进行修改的,暂时没有尝试过。
通过设置discovery.zen.minimum_master_nodes来防止脑裂,表示多少个master候选节点在线时集群可用;
通过设置discovery.zen.ping_timeout来降低网络延时带来的脑裂现象;
节点通过单播来发现和加入进群,设置elasticsearch-discovery服务作为进群发现入口;
serviceAccount是否有必要带验证!!
3.检查并测试集群
elasticsearch.kube.com/_cat/nodes?v
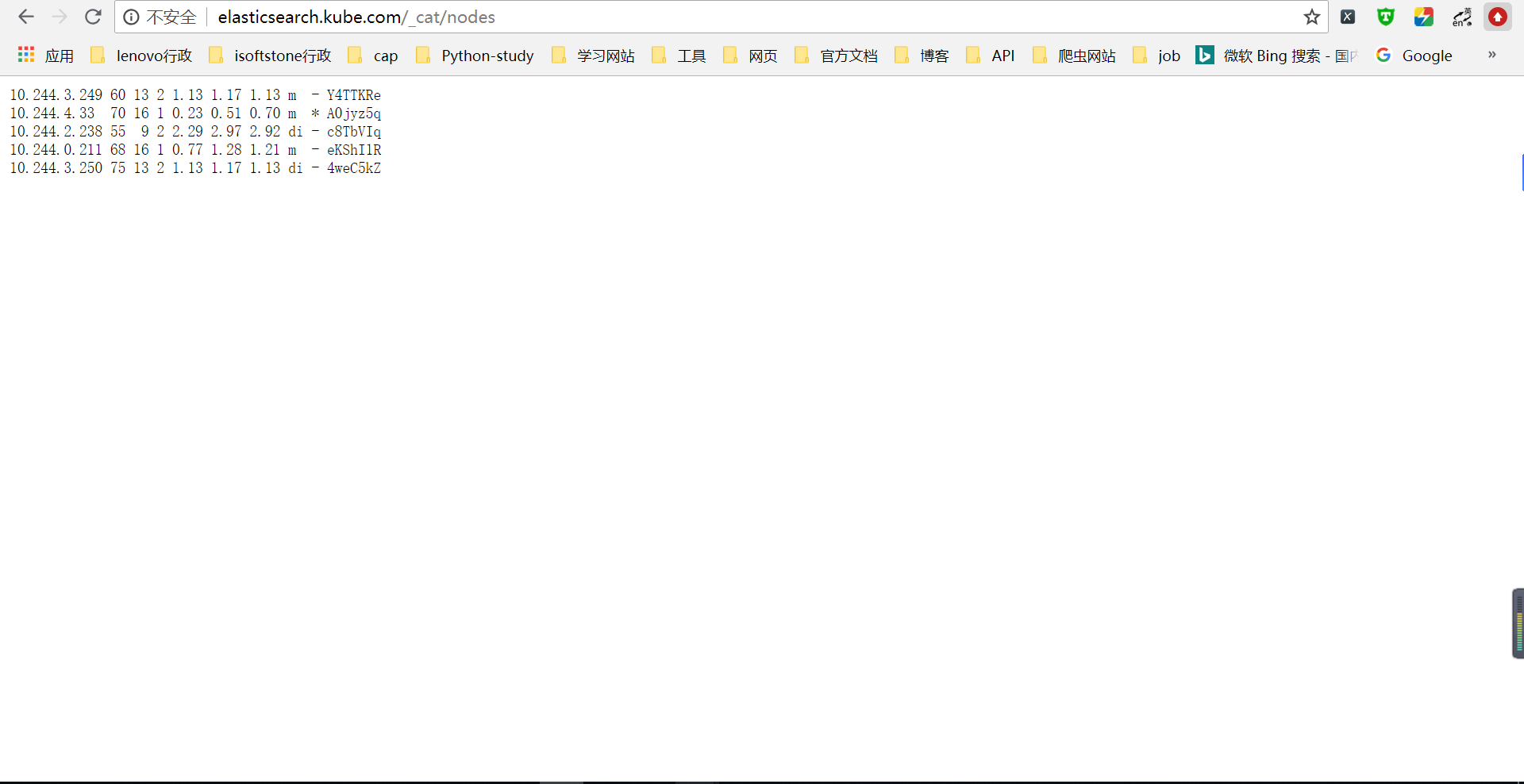
上图中的node.role包含mdi,分别对呀master、data和ingest。
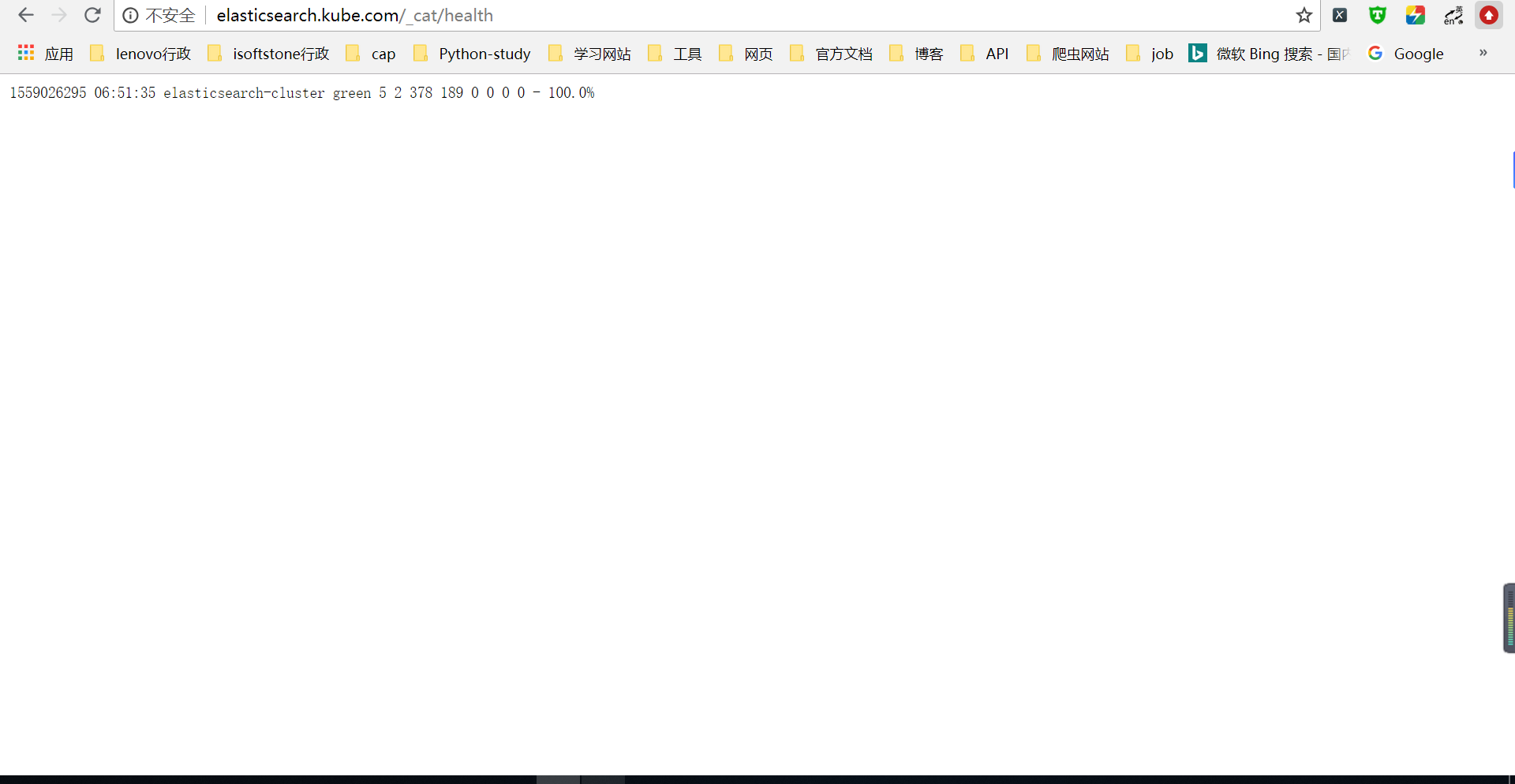
elasticsearch.kube.com/_cat/health?v
4.如果想增加data节点,修改replicas即可
修改data节点deployment的replicas即可
在Kubernetes上部署Kibana和Logstash
5,镜像清单
6.编写YML文件部署kibana
---
kind: Deployment
apiVersion: apps/v1beta2
metadata:
labels:
elastic-app: kibana
name: kibana
namespace: logging
spec:
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
elastic-app: kibana
template:
metadata:
labels:
elastic-app: kibana
spec:
containers:
- name: kibana
image: docker.elastic.co/kibana/kibana:6.2.2
ports:
- containerPort: 5601
protocol: TCP
env:
- name: "ELASTICSEARCH_URL"
value: "http://elasticsearch-service:9200"
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
---
kind: Service
apiVersion: v1
metadata:
labels:
elastic-app: kibana
name: kibana-service
namespace: logging
spec:
ports:
- port: 5601
targetPort: 5601
nodePort: 32179
selector:
elastic-app: kibana
type: NodePort
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
labels:
app: kibana
name: kibana-ingress
namespace: logging
spec:
rules:
- host: kibana.kube.com
http:
paths:
- backend:
serviceName: kibana-service
servicePort: 5601
浏览器访问kibana.kube.com 可以看看ES集群的各项运行指标
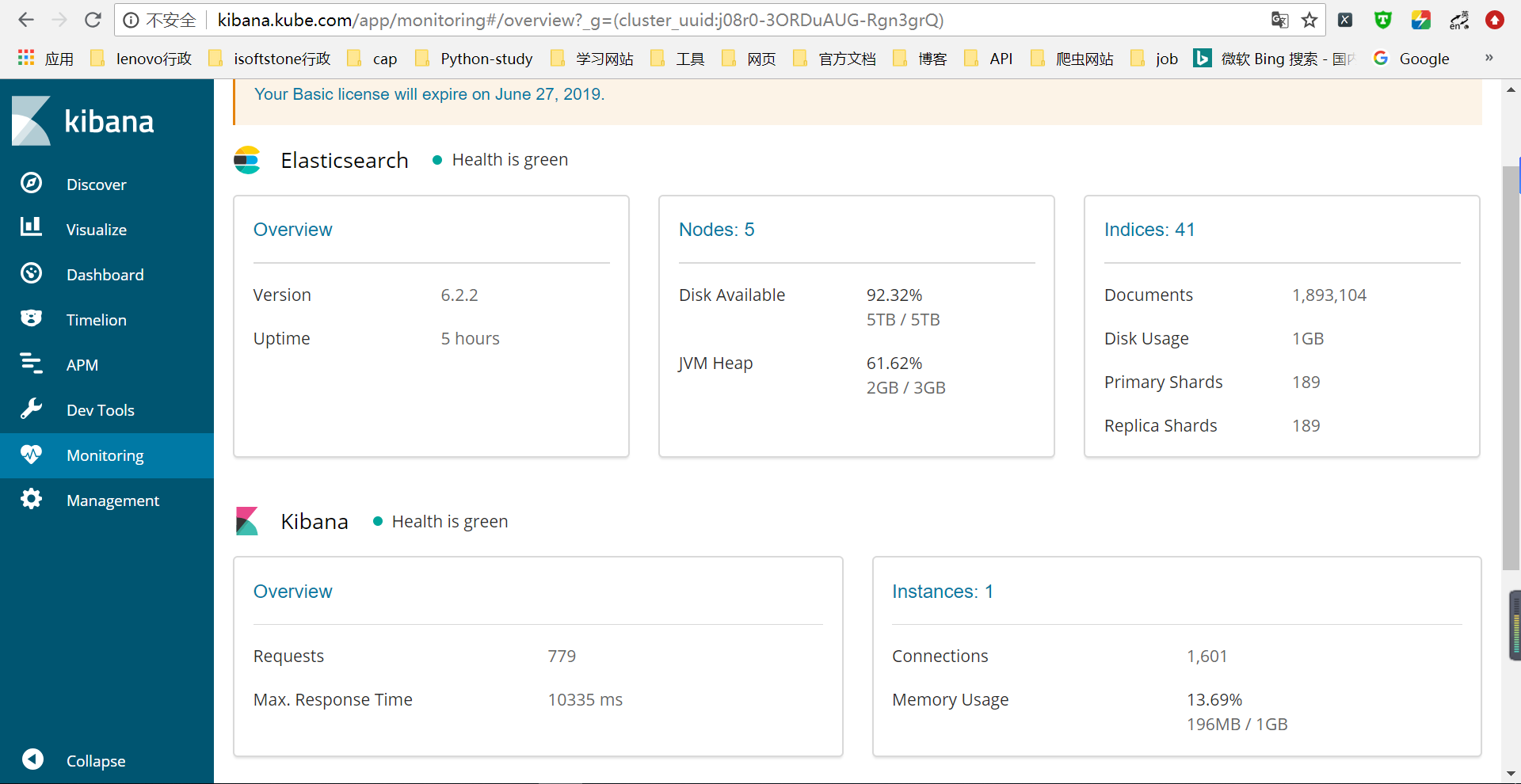
7.编写YML文件部署Logstash
kind: ConfigMap
apiVersion: v1
metadata:
name: logstash-conf
namespace: logging
data:
logstash.conf: |
input {
kafka {
bootstrap_servers => ["10.110.156.67:32200"]
client_id => "test"
group_id => "test"
auto_offset_reset => "latest"
consumer_threads => 5
decorate_events => true
topics => ["beats"]
codec=> "json"
}
}
#filter {
# grok {
# match => { "message" => "%{COMBINEDAPACHELOG}" }
# }
# date {
# match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ]
# }
#}
output {
elasticsearch {
hosts =>["elasticsearch-service:9200"]
}
stdout {
codec => rubydebug
}
}
---
---
kind: Deployment
apiVersion: apps/v1beta2
metadata:
labels:
elastic-app: logstash
name: logstash
namespace: logging
spec:
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
elastic-app: logstash
template:
metadata:
labels:
elastic-app: logstash
spec:
containers:
- name: logstash
image: docker.elastic.co/logstash/logstash:6.2.2
volumeMounts:
- mountPath: /usr/share/logstash/pipeline/logstash.conf
subPath: logstash.conf
name: logstash-conf
ports:
- containerPort: 8080
protocol: TCP
env:
- name: "XPACK_MONITORING_ELASTICSEARCH_URL"
value: "http://elasticsearch-service:9200"
securityContext:
privileged: true
volumes:
- name: logstash-conf
configMap:
name: logstash-conf
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
---
kind: Service
apiVersion: v1
metadata:
labels:
elastic-app: logstash
name: logstash-service
namespace: logging
spec:
ports:
- port: 8080
targetPort: 8080
selector:
elastic-app: logstash
type: NodePort
镜像是我的私库地址,需要修改为你自己的
ES集群地址通过环境变量注入,指向上一篇文章搭建的ES集群服务
For compatibility with container orchestration systems, these environment variables are written in all capitals, with underscores as word separators. The helper translates these names to valid Kibana setting names.
Logstash配置文件通过挂载NFS到容器内部/usr/share/logstash/pipeline路径下
不同的input plugin可能需要开放不同的端口
- 访问Kibana的monitoring,可以看到logstash的相关信息
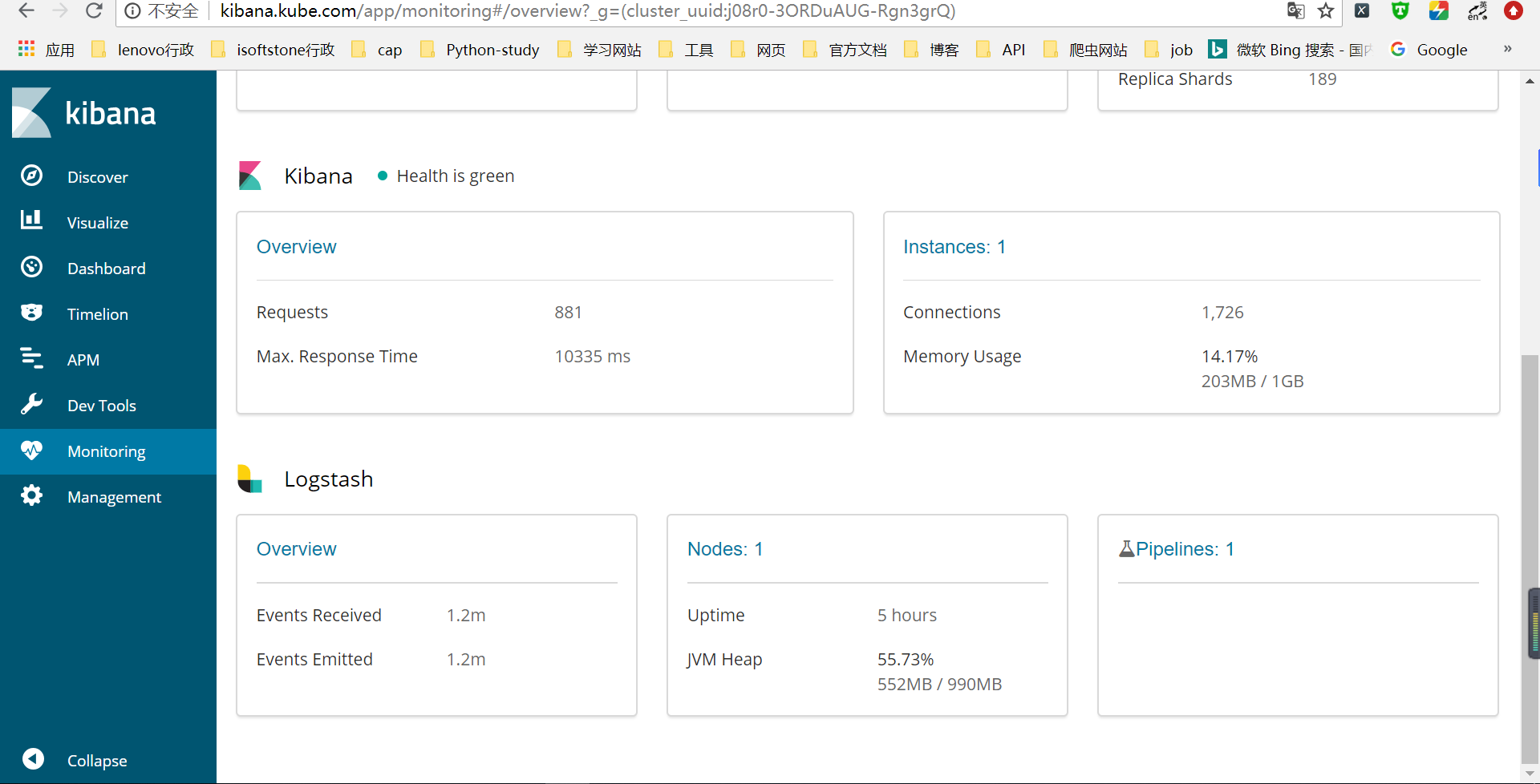
8.编写YML文件部署filebeat
---
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-config
namespace: logging
labels:
k8s-app: filebeat
kubernetes.io/cluster-service: "true"
data:
filebeat.yml: |-
filebeat.config:
prospectors:
path: ${path.config}/prospectors.d/*.yml
reload.enabled: false
modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
#filebeat.autodiscover:
# providers:
# - type: kubernetes
# hints.enabled: true
processors:
- add_cloud_metadata:
- drop_fields:
fields: ["input_type", "offset", "stream", "beat"]
cloud.id: ${ELASTIC_CLOUD_ID}
cloud.auth: ${ELASTIC_CLOUD_AUTH}
#output.elasticsearch:
# hosts: ['${ELASTICSEARCH_HOST:elasticsearch}:${ELASTICSEARCH_PORT:9200}']
# username: ${ELASTICSEARCH_USERNAME}
# password: ${ELASTICSEARCH_PASSWORD}
output.kafka:
enabled: true
hosts: ["10.110.156.67:32200"]
topic: beats
compression: gzip
max_message_bytes: 1000000
#output.logstash:
# hosts: ["10.110.156.67:30333"]
---
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-prospectors
namespace: logging
labels:
k8s-app: filebeat
kubernetes.io/cluster-service: "true"
data:
kubernetes.yml: |-
- type: docker
combine_partial: true
containers:
path: "/var/lib/docker/containers"
stream: "stdout"
ids:
- "*"
json.keys_under_root: true
json.overwrite_keys: true
include_lines: ['ERR', 'WARN']
exclude_lines: ['es-cluster','logstash','=>']
exclude_files: ['06a97da5eee5f5ecdc77bba65093bda4468692234a663676e9053e9f40e618a1*.log']
processors:
- add_kubernetes_metadata:
in_cluster: true
---
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: filebeat
namespace: logging
labels:
k8s-app: filebeat
kubernetes.io/cluster-service: "true"
spec:
template:
metadata:
labels:
k8s-app: filebeat
kubernetes.io/cluster-service: "true"
spec:
serviceAccountName: filebeat
terminationGracePeriodSeconds: 30
containers:
- name: filebeat
image: docker.elastic.co/beats/filebeat:6.2.2
args: [
"-c", "/etc/filebeat.yml",
"-e",
]
env:
- name: ELASTICSEARCH_HOST
value: elasticsearch-service.logging
- name: ELASTICSEARCH_PORT
value: "9200"
- name: ELASTICSEARCH_USERNAME
value: elastic
- name: ELASTICSEARCH_PASSWORD
value: changeme
- name: ELASTIC_CLOUD_ID
value:
- name: ELASTIC_CLOUD_AUTH
value:
securityContext:
runAsUser: 0
#resources:
# limits:
# memory: 200Mi
# requests:
# cpu: 100m
# memory: 100Mi
volumeMounts:
- name: config
mountPath: /etc/filebeat.yml
readOnly: true
subPath: filebeat.yml
- name: prospectors
mountPath: /usr/share/filebeat/prospectors.d
readOnly: true
- name: data
mountPath: /usr/share/filebeat/data
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
- name: varlog
mountPath: /var/log/
readOnly: true
- name: datadockercontainers
mountPath: /data/docker/containers
readOnly: true
volumes:
- name: config
configMap:
defaultMode: 0600
name: filebeat-config
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
- name: varlog
hostPath:
path: /var/log/
- name: datadockercontainers
hostPath:
path: /data/docker/containers
- name: prospectors
configMap:
defaultMode: 0600
name: filebeat-prospectors
- name: data
emptyDir: {}
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: filebeat
subjects:
- kind: ServiceAccount
name: filebeat
namespace: logging
roleRef:
kind: ClusterRole
name: filebeat
apiGroup: rbac.authorization.k8s.io
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRole
metadata:
name: filebeat
labels:
k8s-app: filebeat
rules:
- apiGroups: [""] # "" indicates the core API group
resources:
- namespaces
- pods
verbs:
- get
- watch
- list
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: filebeat
namespace: logging
labels:
k8s-app: filebeat
---
9.编写YML文件部署kafka
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: datadir-kafka-0
namespace: kafka
labels:
app: kafka
podindex: "0"
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 20Gi
persistentVolumeReclaimPolicy: Retain
storageClassName: nfs
nfs:
path: "/data/mongodb/siot/kafka/datadir-kafka-0"
server: 10.110.156.60
#hostPath:
# path: "/data/kafka/datadir-kafka-0"
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: datadir-kafka-1
namespace: kafka
labels:
app: kafka
podindex: "1"
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 20Gi
persistentVolumeReclaimPolicy: Retain
storageClassName: nfs
nfs:
path: "/data/mongodb/siot/kafka/datadir-kafka-1"
server: 10.110.156.60
#hostPath:
# path: "/data/kafka/datadir-kafka-1"
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: datadir-kafka-2
namespace: kafka
labels:
app: kafka
podindex: "2"
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 20Gi
persistentVolumeReclaimPolicy: Retain
storageClassName: nfs
nfs:
path: "/data/mongodb/siot/kafka/datadir-kafka-2"
server: 10.110.156.60
#hostPath:
# path: "/data/kafka/datadir-kafka-2"
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: datadir-kafka-0
namespace: kafka
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 19Gi
storageClassName: nfs
selector:
matchLabels:
app: kafka
podindex: "0"
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: datadir-kafka-1
namespace: kafka
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 19Gi
storageClassName: nfs
selector:
matchLabels:
app: kafka
podindex: "1"
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: datadir-kafka-2
namespace: kafka
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 19Gi
storageClassName: nfs
selector:
matchLabels:
app: kafka
podindex: "2"
---
apiVersion: v1
kind: Service
metadata:
name: zookeeper
namespace: kafka
spec:
ports:
- port: 2181
name: client
selector:
app: zookeeper
---
apiVersion: v1
kind: Service
metadata:
name: zoo
namespace: kafka
spec:
ports:
- port: 2888
name: peer
- port: 3888
name: leader-election
clusterIP: None
selector:
app: zookeeper
---
apiVersion: apps/v1beta1
kind: StatefulSet
metadata:
name: zoo
namespace: kafka
spec:
serviceName: "zoo"
replicas: 5
template:
metadata:
labels:
app: zookeeper
spec:
terminationGracePeriodSeconds: 10
containers:
- name: zookeeper
image: solsson/zookeeper-statefulset:3.4.9
env:
- name: ZOO_SERVERS
value: server.1=zoo-0.zoo:2888:3888:participant server.2=zoo-1.zoo:2888:3888:participant server.3=zoo-2.zoo:2888:3888:participant server.4=zoo-3.zoo:2888:3888:participant server.5=zoo-4.zoo:2888:3888:participant
ports:
- containerPort: 2181
name: client
- containerPort: 2888
name: peer
- containerPort: 3888
name: leader-election
volumeMounts:
- name: datadir
mountPath: /data
- name: conf
mountPath: /conf
volumes:
- name: conf
emptyDir: {}
- name: datadir
emptyDir: {}
---
apiVersion: v1
kind: Service
metadata:
name: broker
namespace: kafka
spec:
ports:
- port: 9092
clusterIP: None
selector:
app: kafka
---
apiVersion: v1
kind: Service
metadata:
name: kafka
namespace: kafka
spec:
type: NodePort
ports:
- port: 9092
nodePort: 32200
selector:
app: kafka
---
apiVersion: apps/v1beta1
kind: StatefulSet
metadata:
name: kafka
namespace: kafka
spec:
serviceName: "broker"
replicas: 3
template:
metadata:
labels:
app: kafka
spec:
terminationGracePeriodSeconds: 10
containers:
- name: broker
image: solsson/kafka-persistent:0.10.1
ports:
- containerPort: 9092
command:
- sh
- -c
- "./bin/kafka-server-start.sh config/server.properties --override broker.id=$(hostname | awk -F'-' '{print $2}')"
volumeMounts:
- name: datadir
mountPath: /opt/kafka/data
volumeClaimTemplates:
- metadata:
name: datadir
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 19Gi
---
9.创建kafka topic
apiVersion: batch/v1
kind: Job
metadata:
name: topic-create
namespace: kafka
spec:
template:
metadata:
name: topic-create
spec:
restartPolicy: Never
containers:
- name: kafka-elk
image: solsson/kafka-persistent:0.10.1
command:
- ./bin/kafka-topics.sh
- --zookeeper
- zookeeper:2181
- --create
- --topic
- beats
- --partitions
- "6"
- --replication-factor
- "1"

开源、云原生的融合云平台
更多推荐
 2
2 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)