大型分布式系统架构中的“let it crash”思想
原创文章,转载请注明 “let it crash”思想源于Erlang。Erlang的稳定性是众所周知的。 而Erlang的稳定,深层原因就在于“let it crash”思想。在讲什么是“let it crash”思想之前,我们先来看看其所解决的问题或背景。 编写大型的分布式程序,代码中往往会遇到这样或那样的异常,这些许许多多的异常很多甚
原创文章,转载请注明
“let it crash”思想源于Erlang。Erlang的稳定性是众所周知的。
而Erlang的稳定,深层原因就在于“let it crash”思想。在讲什么是“let it crash”思想之前,我们先来看看其所解决的问题或背景。
编写大型的分布式程序,代码中往往会遇到这样或那样的异常,这些许许多多的异常很多甚至是纠缠不清的。如果尝试去根据预想的不同异常来编写代码处理,是非常困难,有时候甚至是不现实的,因为有时候你数不清有多少异常情况,在哪里会出现,并且编写防御异常的代码有可能产生新的异常。
于是有人提出了“let it crash”思想,it一般指的是独立的进程。其主要思想就是分布式系统中的进程有异常,不进行防御代码的编写,而是由它奔溃。然后有此进程的监督进程进行重启,当然,奔溃前的正常状态要做到可以恢复,也就是要做到进程状态持久化,这个技术现在先不展开。
核心的关键就是进程奔溃,监督者重启,状态恢复,继续处理。在外面看来,数据处理的流程没有中断过。看如下示例图:
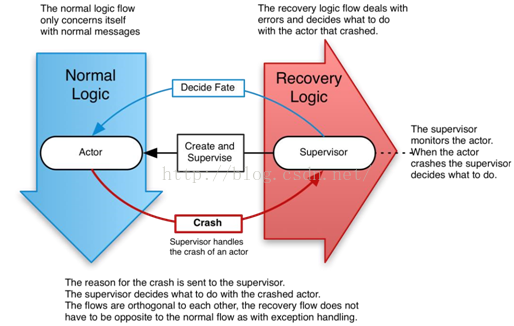
此图很好地诠释了监督者与普通进程之间的关系。当然,不是说进程中的所有异常都不处理,有些异常也是需要在进程内部处理的。具体哪些异常处理,哪些异常不处理,这个视具体情况斟酌。

开源、云原生的融合云平台
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)