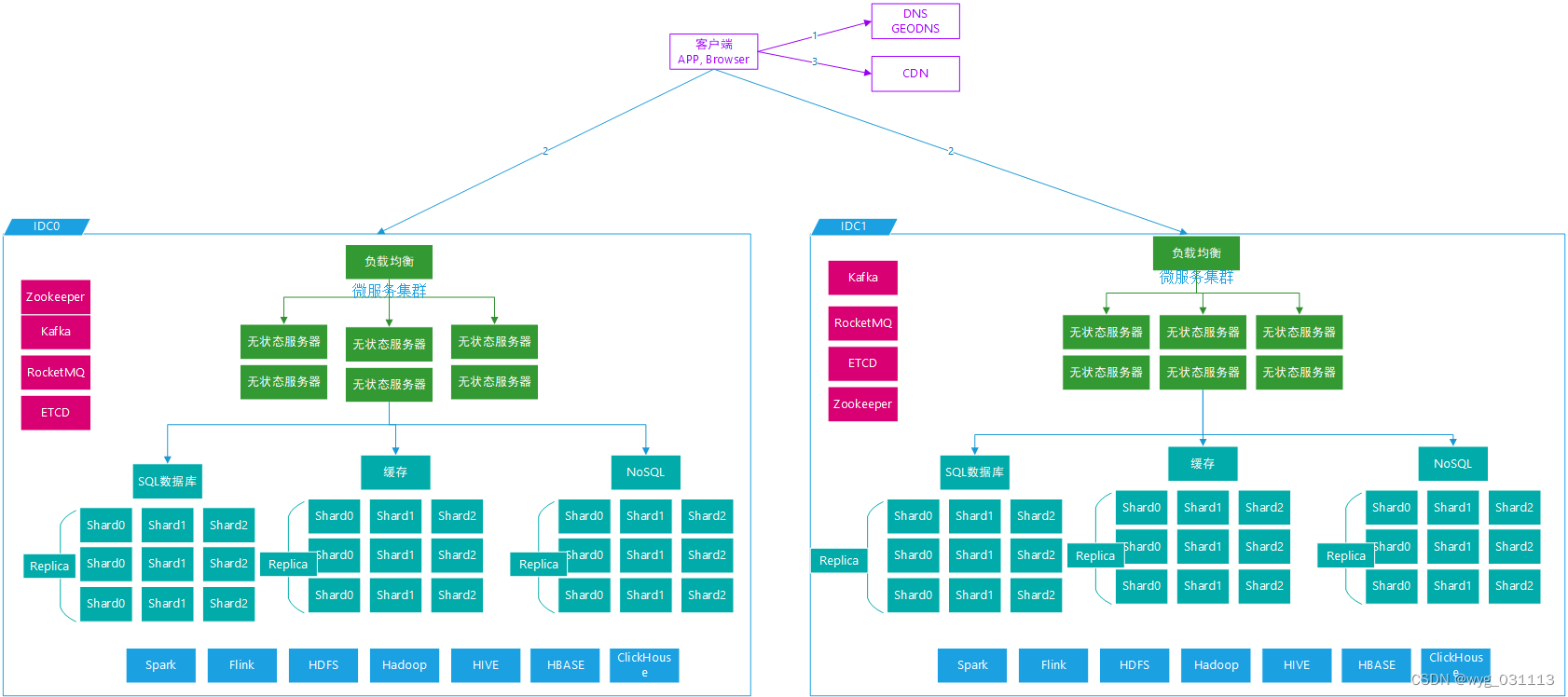
系统架构设计
对于计算:采用集群化+负载均衡对于:采用分片,复制集,读写分离再加上无处不在的。
·

系统核心指标在设计系统前要明确:
- 延迟:实时(明确多少ms), 离线
- 一致性:弱一致,强一致,最终一致
- QPS, TPS 峰值2倍平均值,秒杀?
- 存储数据量,时间周期,是否大数据
- DAU,
- 网络带宽限制
- 核心业务流程是什么,非核心流程是否支持降级
- 系统级:高可靠,高可用,高性能,好运维
- 软件级:流程图,核心算法,扩展性,设计模式
- 现在系统利用:云存储,公司现在有可利用基础设施
高性能
- 客户端内部缓存
- 客户端到服务器之间缓存:CDN,网络专线
- 数据库前加缓存
- Sessioin等信息共享NoSQL
- 数据库分片,读写分离
- web层无关态集群+负载均衡
- GeoDNS 就近原则,边缘计算存储
- 异步,解耦,削峰:消息队列
- 离线预计算,空间换时间:bloom filter
- 压缩
对于无状态计算:采用集群化+负载均衡
对于有状态存储:采用分片,复制集,读写分离
再加上无处不在的缓存
高可靠&高可用
- 集群
- 数据冗余
- 双机房容灾
- 失败探测方法与恢复
- 限流&降级
总节结:系统不能存在单点,有副本有冗余,出问题时能迅速让副本顶上。
好运维
- 监控告警要完善:直观明了发现问题。
- 日常更新好灰度:不要出现更新就影响所有用户的情况。
- 日志全面:出问题好定位。
- 扩缩容易操作,自动化程序高
- 好恢复:人工操作失败好回滚
安全性
- 加密,https
- ddos: 限流
- 鉴权:sso token jwt kerberos
客户端
- TCP
- HTTP
- WebSockets
无状态问题少,有状态很棘手
分片问题:
- 分片不均衡怎么办?
- 分片key怎么选
- 增加减少分片时怎么均衡?
- 分片中出现明星效应怎么办?
- 事务
- 元数据管理,元数据一致性(版本号?lease?)
- 智能客户端?服务器代理?
- 分片方式:hash、一致性hash、range based
- 参考:redis, kafka, hdfs, mongodb, tidb,tikv中的解决方案
多副本或主从问题:
- 一致性:
- 强一致性算法?固定一台机器为master,进行读写。配合上RAFT Paxos算法
- 大多数原则(Quorum consensus)?写入大多数,或者读大多数。向量时钟解决读一致
- 主动检测恢复?hash tree or Merkle tree。主动检测存储数据一致性。 raid?
- 弱一致性。
- 最终一致性
- 写入性能
cache问题:
- 不一致
- 雪崩
- 冷启动

开源、云原生的融合云平台
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)