docker底层之namespace
现在在搞docker和kubernetes,鉴于lxc和docker的底层技术同源性,这里将以前搞lxc时写的总结分享出来,lxc相对于docker比较简单一些,理解了lxc对docker的低层理解也会比较容易,同时也防止文档丢失,逐渐把以前的搬到博客里,也方便自己回顾。
鉴于docker底层和lxc底层相同,这里整理下研究lxc时对于namespace的研究。
在其他虚拟化的系统中,一台物理计算机可以运行多个内核,可能是并行的多个不同的操作系统。而容器只使用一个内核在一台物理计算机上运行,通过命名空间隔离资源来虚拟os运行环境,但核心的底层服务则由一个kernel完成。与应用相关的全局资源都通过命名空间抽象起来,使得可以将一组进程放置到容器中,各个容器彼此隔离。隔离可以使容器的成员与其他容器毫无关系。但也可以通过允许容器进行一定的共享,来降低容器之间的分隔。例如,容器可以设置为使用自身的PID集合,但仍然与其他容器共享部分文件系统。本质上,命名空间建立了系统的不同视图。此前的每一项全局资源都必须包装到容器数据结构中,只有资源和包含资源的命名空间构成的二元组仍然是全局唯一的。虽然在给定容器内部资源是自足的,但无法提供在容器外部具有唯一性的ID。
新的命名空间可以用下面两种方法创建。
Ø 在用fork或clone系统调用创建新进程时,有特定的选项可以控制是与父进程共享命名空间,还是建立新的命名空间。该选项就是一些标志位,每个命名空间都有一个对应的标志:
#define CLONE_NEWUTS 0x04000000 /* 创建新的utsname组 */
#define CLONE_NEWIPC 0x08000000 /* 创建新的IPC命名空间 */
#define CLONE_NEWUSER 0x10000000 /* 创建新的用户命名空间 */
#define CLONE_NEWPID 0x20000000 /* 创建新的PID命名空间 */
#define CLONE_NEWNET 0x40000000 /* 创建新的网络命名空间 */
Ø unshare系统调用将进程的某些部分从父进程分离,其中也包括命名空间。
命名空间的实现需要两个部分:每个子系统的命名空间结构,将此前所有的全局组件包装到命名空间中;将给定进程关联到所属各个命名空间的机制。structnsproxy用于汇集指向特定于子系统的命名空间包装器的指针:
Ø UTS命名空间包含了运行内核的名称、版本、底层体系结构类型等信息。
Ø IPC命名空间包含了与进程间通信有关的信息。
Ø MNT命名空间包含了文件系统的视图。
Ø PID命名空间包含了有关进程ID的信息。
Ø USER命名空间包含了用于限制每个用户资源使用的信息,最近的更新包含了容器权限控制的实现部分。
Ø NET命名空间包含所有网络相关的参数。目前只是部分还不够完善。
下面分别说明下各个命名空间。
1.1.1. PID命名空间
Linux用ID来管理进程,常用的有PID,但每个进程除了PID之外,还有其他的ID。共有四种ID定义在pid_type中。PIDTYPE_MAX表示ID类型的数目:
enum pid_type
{
PIDTYPE_PID,
PIDTYPE_PGID,
PIDTYPE_SID,
PIDTYPE_MAX
};
处于某个线程组中的所有进程都有统一的线程组ID(TGID)。如果进程没有使用线程,则其PID和TGID相同。
线程组中的主进程被称作组长(group leader)。通过clone创建的所有线程的task_struct的group_leader成员,会指向组长的task_struct实例。
独立进程可以合并成进程组,进程组成员的task_struct的pgrp属性值都是相同的,即进程组组长的 PID。进程组简化了向组的所有成员发送信号的操作。
几个进程组可以合并成一个会话。会话中的所有进程都有同样的会话ID,保存在task_struct的session成员中。SID可以使用 setsid系统调用设置。终端中运行的程序一般具有相同的SID。
PID命名空间可以是多层嵌套,一个命名空间是父命名空间,衍生了两个子命名空间。如果每个容器都配置了新的命名空间,如果容器为系统级容器,每个容器都有自身的init进程,PID为0,子命名空间都有PID为0的init进程,以及PID分别为2和3的进程。子命名空间不了解父命名空间,但父命名空间知道子命名空间的存在,也可以看到其中执行的所有进程,因此子命名空间的进程ID在父命名空间中是唯一的,这也就说明了自命名空间拥有多个pid,这些pid分别对应其以上的命名空间。那么顶层ID为全局ID,子命名空间ID为局部ID。
全局ID是在内核本身和初始命名空间中的唯一ID号,在系统启动期间开始的init进程即属于初始命名空间。对每个ID类型,都有一个给定的全局 ID,保证在整个系统中是唯一的。局部ID属于某个特定的命名空间,不具备全局有效性。对每个ID类型,它们在所属的命名空间内部有效,但类型相同、值也相同的ID可能出现在不同的命名空间中。
全局PID和TGID直接保存在task_struct中,分别是task_struct的pid和tgid成员:
struct task_struct {
...
pid_t pid;
pid_t tgid;
...
}
PID命名空间用pid_namespace表示:
structpid_namespace {
struct kref kref;
struct pidmap pidmap[PIDMAP_ENTRIES];
int last_pid;
struct task_struct *child_reaper;
struct kmem_cache *pid_cachep;
unsigned int level;
struct pid_namespace *parent;
#ifdefCONFIG_PROC_FS
struct vfsmount *proc_mnt;
#endif
#ifdefCONFIG_BSD_PROCESS_ACCT
struct bsd_acct_struct *bacct;
#endif
gid_t pid_gid;
int hide_pid;
int reboot; /*group exit code if this pidns was rebooted */
};
child_reaper指向的进程作用相当于全局命名空间的init进程,其中一个目的是对孤儿进程进行回收。Level则表明自己所处的命名空间在系统命名空间里面的深度,这是一个重要的标记,因为层次高的命名空间可以看到低级别的所有信息。系统的命名空间从0开始技术,然后累加。parent是指向父命名空间的指针。
PID的管理围绕两个数据结构展开:structpid是内核对PID的内部表示,而structupid则表示特定的命名空间中可见的信息。两个结构的定义如下:
struct pid
{
atomic_tcount;//引用计数
structhlist_head tasks[PIDTYPE_MAX];//该pid被使用的task链表
structrcu_head rcu;//互斥访问
intlevel;//该pid所能到达的最大深度
structupid numbers[1];//每一层次(level)的upid
}
一个pid可以属于不同的级别,每一级别又包含一个upid
struct upid
{
intnr;//真正的pid值
structpid_namespace *ns;//该nr属于哪个pid_namespace
structhlist_node pid_chain;//所有upid的hash链表 find_pid
}
struct pid的定义首先是一个引用计数器count。tasks是一个数组,每个数组项都是一个散列表头,对应于一个ID类型。这样做是必要的,因为一个ID可能用于几个进程。所有共享同一给定ID的task_struct实例,都通过该列表连接起来。一个进程可能在多个命名空间中可见,而其在各个命名空间中的局部ID各不相同。level表示可以看到该进程的命名空间的数目(换言之,即包含该进程的命名空间在命名空间层次结构中的深度),而numbers是一个upid实例的数组,每个数组项都对应于一个命名空间。注意该数组形式上只有一个数组项,如果一个进程只包含在全局命名空间中,那么确实如此。由于该数组位于结构的末尾,因此只要分配更多的内存空间,即可向数组添加附加的项。对于structupid,nr表示ID的数值,ns是指向该ID所属的命名空间的指针。所有的upid实例都保存在一个散列表中。
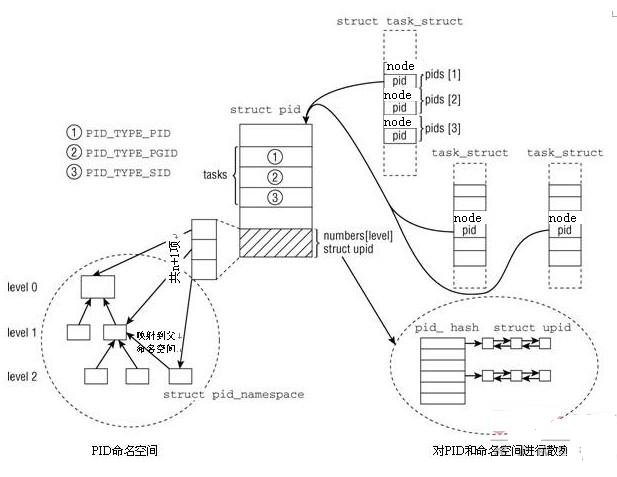
一个task_struct通过pid_link的hlist_node挂接到struct pid的链表上面去。同时task_struct又是用过pid_link找到pid,通过pid遍历tasks链表又能够得到所有的任务,当然也可以读取numbers数字获取每一个命名空间里面的数字信息。
由于所有共享同一ID的task_struct实例都按进程存储在一个散列表中,因此需要在structtask_struct中增加一个散列表元素:
struct task_struct {
...
/* PID与PID散列表的联系。 */
struct pid_link pids[PIDTYPE_MAX];
...
};
辅助数据结构pid_link可以将task_struct连接到表头在struct pid中的散列表上:
struct pid_link
{
struct hlist_node node;
struct pid *pid;
};
pid指向进程所属的pid结构实例,node用作散列表元素。
为在给定的命名空间中查找对应于指定PID数值的pid结构实例,使用了一个散列表:
static struct hlist_head *pid_hash;
1.1.2. MNT命名空间
进程创建的时候,每一个进程都有自己的文件挂载点,定义在structtask_struct中:
structtask_struct {
……
/* filesysteminformation */
struct fs_struct *fs;
/* open fileinformation */
struct files_struct *files;
/* namespaces*/
struct nsproxy *nsproxy;
……
}
structfs_struct {
int users;
spinlock_t lock;
seqcount_t seq;
int umask;
int in_exec;
struct path root, pwd;
};
在一个系统启动的时候,0号进程就设置好了自己所在的根目录以及当前目录。在创建子进程的时候,通过CLONE_FS来指明父子之间的共享信息,如果设置了两者共享同一个结构,没有设置标记的话,子进程创建一个新的拷贝,两者之间互不影响。如果设置了CLONE_FS,通过chroot(2), chdir(2), or umask(2)的调用结果两者之间会相互影响,反之两者是独立的。
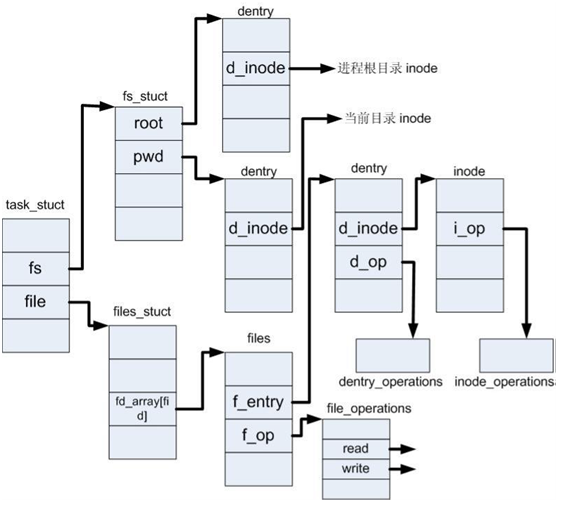
老的chroot机制只会更改fs_struct中的root指针指向新的目录的dentry结构,pwd不会更改,新的MNT命名空间技术不但更改了pwd和root,而使用的是mount,这将会重新创建一个vfs_mount实例。
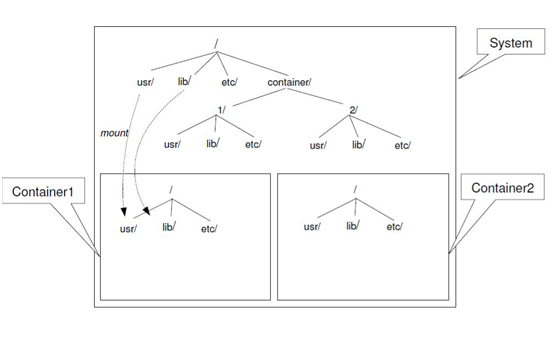
举例说明MNT命名空间的效果:
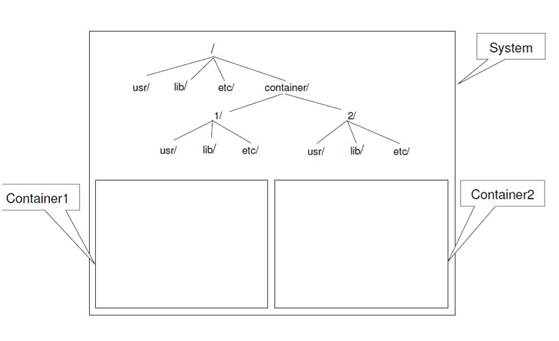
在系统目录里面创建一个container目录,在这个目录里面为每一个容器创建了独立的目录,为1和2。在目录1和2里面分别创建相应容器的根目录文件系统。在容器里看到的文件系统视图如下所示。
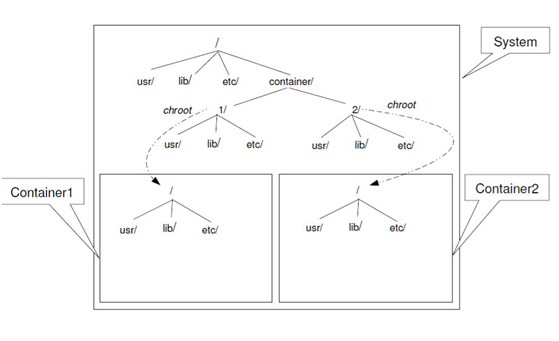
容器1和容器2之间的文件系统是互不可见的,而且容器也看不到除了根目录之外的其他文件目录。为了和系统或者其他容器共享文件,需要映射特定目录到容器的根文件系统,达到部分隔离以及共享的效果。
1.1.3. NET命名空间
NET的命名空间隔离做的工作相对而言是最多的,在目前的内核里面路由表,arp表,netfilter表,设备等等都已经命名空间化了,虽然共享一个网络协议栈,但是协议栈在处理数据的时候都会从各自的命名空间中取出相关的配置,这样数据就被隔离开来,看上去像多个协议栈。
NET命名空间用structnet表示:
struct net {
atomic_t passive; /* To decided when the network
* namespace should be freed.
*/
atomic_t count; /* To decided when the network
* namespace should be shut down.
*/
#ifdefNETNS_REFCNT_DEBUG
atomic_t use_count; /* To track references we
* destroy on demand
*/
#endif
spinlock_t rules_mod_lock;
struct list_head list; /* list of networknamespaces */
struct list_head cleanup_list; /* namespaces ondeath row */
struct list_head exit_list; /* Use onlynet_mutex */
struct proc_dir_entry *proc_net;
struct proc_dir_entry *proc_net_stat;
#ifdefCONFIG_SYSCTL
struct ctl_table_set sysctls;
#endif
struct sock *rtnl; /* rtnetlink socket */
struct sock *genl_sock;
struct list_head dev_base_head;
struct hlist_head *dev_name_head;
struct hlist_head *dev_index_head;
unsigned int dev_base_seq; /* protected by rtnl_mutex */
/* core fib_rules */
struct list_head rules_ops;
struct net_device *loopback_dev; /* The loopback */
struct netns_core core;
struct netns_mib mib;
struct netns_packet packet;
struct netns_unix unx;
struct netns_ipv4 ipv4;
#ifIS_ENABLED(CONFIG_IPV6)
struct netns_ipv6 ipv6;
#endif
#ifdefined(CONFIG_IP_DCCP) || defined(CONFIG_IP_DCCP_MODULE)
struct netns_dccp dccp;
#endif
#ifdefCONFIG_NETFILTER
struct netns_xt xt;
#ifdefined(CONFIG_NF_CONNTRACK) || defined(CONFIG_NF_CONNTRACK_MODULE)
struct netns_ct ct;
#endif
struct sock *nfnl;
struct sock *nfnl_stash;
#endif
#ifdefCONFIG_WEXT_CORE
struct sk_buff_head wext_nlevents;
#endif
struct net_generic __rcu *gen;
/* Note : following structs are cache linealigned */
#ifdefCONFIG_XFRM
struct netns_xfrm xfrm;
#endif
struct netns_ipvs *ipvs;
};
Struct net这个结构实在较大,里面基本包含的是链路层以上的内容。在一个NET命名空间创建的时候,会做一些初始化。系统定义了一个回调函数,让感兴趣的模块注册。结构如下:

一个新的NET命名空间被创建的时候,注册模块的init被调用。同理,一个NET命名空间销毁的时候,exit也会被调用。
MNT命名空间通过mount一些公共的目录进行共享,NET命名空间与外界联系则有多种方式,通常会使用设备对,搭建网桥的方式与容器外通信。一个设备对即A设备接收到的时候自动发送到B设备,反之亦然。
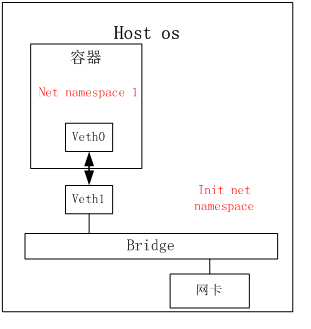
对于容器来说,veth0需要配置一个IP地址,但是veth1和物理网卡配置在同一个桥接设备上。Veth0和veth1是网络设备对。Veth1和网卡是通过桥接来完成转发,但是veth0和veth1之间是通过设备对来完成数据转发,这样数据就在netnamespace 1和init netnamespace之间传输。
NET命名空间隔离的内容比较多,例如ip分片、路由表和netfilter等。
1.1.4. UTS命名空间
UTS命名空间很简单,所有相关信息都汇集到下列结构的一个实例中:
struct uts_namespace {
struct kref kref;
struct new_utsname name;
};
kref是一个嵌入的引用计数器,可用于跟踪内核中有多少地方使用了structuts_namespace的实例。uts_namespace所提供的属性信息本身包含在structnew_utsname中:
structnew_utsname
{
charsysname[65];//系统名称
charnodename[65];//主机名
charrelease[65];//内核版本号
charversion[65];//内核版本日期
charmachine[65];//体系结构
chardomainname[65];
}
各个字符串分别存储了系统的名称(Linux...)、内核发布版本、机器名,等等。使用uname工具可以取得这些属性的当前值,也可以在/proc/sys/kernel/中看到:
初始设置保存在init_uts_ns中:
struct uts_namespace init_uts_ns = {
.name = {
.sysname = UTS_SYSNAME,
.nodename = UTS_NODENAME,
.release = UTS_RELEASE,
.version = UTS_VERSION,
.machine = UTS_MACHINE,
.domainname = UTS_DOMAINNAME,
},
};
相关的预处理器常数在内核中各处定义。UTS结构的某些部分不能修改。例如,把sysname换成Linux以外的其他值是没有意义的,但改变机器名是可以的。
1.1.5. IPC命名空间
IPC是一个较为简单的扁平化进程间通信工具,命名空间之间不存在层级。
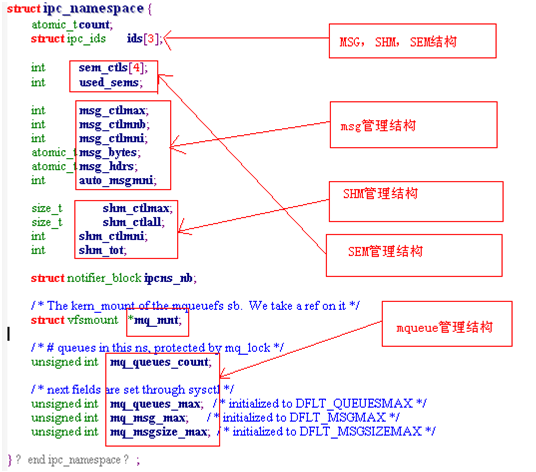
IPC 命名空间之间的关系是并列的:
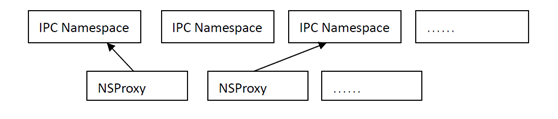
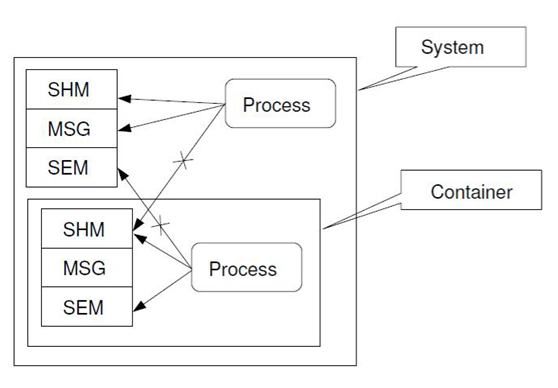
共享内存,消息队列和信号量的实现比较简单,这里不放代码分析了。

开源、云原生的融合云平台
更多推荐
 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)