Kubernetes1.6新特性:全面支持多颗GPU
(一) 背景资料GPU就是图形处理器,是Graphics Processing Unit的缩写。电脑显示器上显示的图像,在显示在显示器上之前,要经过一些列处理,这个过程有个专有的名词叫“渲染" ,以前计算机上是没有GPU的,都是通过CPU来进行“渲染”处理的,这些涉及到“渲染”的计算工作非常耗时,占用了CPU的大部分时间。之后出现了GPU,是专门为了实现“渲染”这种计算工作的,用来将CPU解
(一) 背景资料
GPU就是图形处理器,是Graphics Processing Unit的缩写。电脑显示器上显示的图像,在显示在显示器上之前,要经过一些列处理,这个过程有个专有的名词叫“渲染" ,以前计算机上是没有GPU的,都是通过CPU来进行“渲染”处理的,这些涉及到“渲染”的计算工作非常耗时,占用了CPU的大部分时间。之后出现了GPU,是专门为了实现“渲染”这种计算工作的,用来将CPU解放出来,GPU是专为执行复杂的数学和几何计算而设计的,这些计算是“渲染”所必需的。
下面看看百度百科上CPU同GPU的对比图,其中绿色的是计算单元:

可以看出来GPU有大量的计算单元,所以GPU是专门为“渲染”这种计算工作设计的。
(二) 应用领域
最开始同GPU相关的应用只是简单地停留在图形相关应用上,比如游戏中3D图形“渲染”等图像处理应用,现在GPU的应用已经非常广泛的,在游戏、娱乐、科研、医疗、互联网等涉及到大规模计算的领域都有GPU应用的存在,比如高性能计算应用、机器学习应用、人工智能应用、自动驾驶应用、虚拟现实应用、自然语言处理应用等等。
1、下面看看Nvidia提供的深度学习领域使用GPU的分析结果:
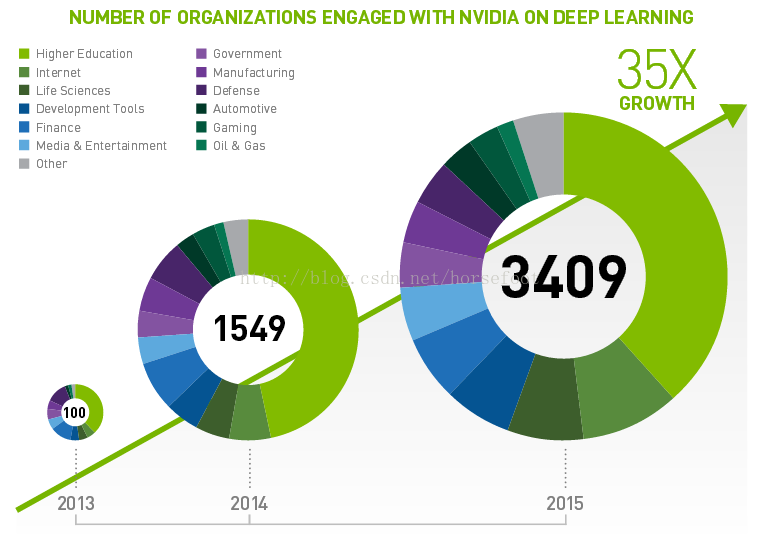
可以看出来从2013年到2015年在深度学习领域呈现出爆发性增长的趋势。
2、下面看看Nvidia提供的资料:
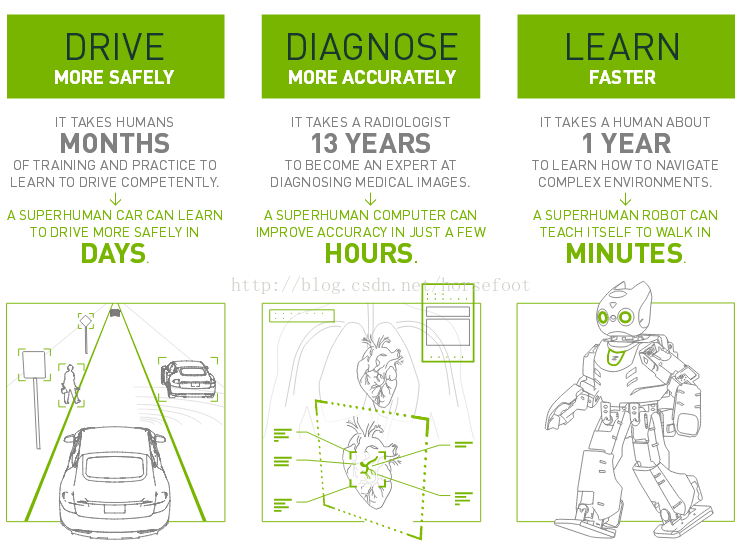
使用GPU来实现深度学习应用后,在自动驾驶、医疗诊断和机器学习三方面效率提高的十分明显。
(三) Kubernetes 1.3中支持GPU的实现
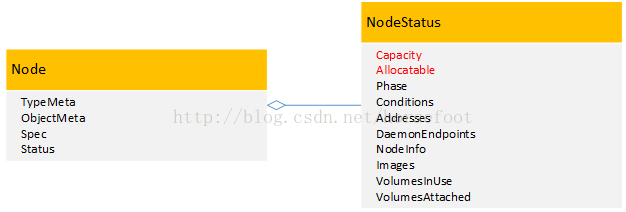
在kubernetes1.3中提供了对Nvidia品牌GPU的支持,在kubernetes管理的集群中每个节点上,通过将原有的Capacity和Allocatable变量进行扩展,增加了一个针对Nvidia品牌GPU的α特性:alpha.kubernetes.io/nvidia-gpu。其中Capacity变量表示每个节点中实际的资源容量,包括cpu、memory、storage、alpha.kubernetes.io/nvidia-gpu,而Allocatable变量表示每个节点中已经分配的资源容量,同样包括包括cpu、memory、storage、alpha.kubernetes.io/nvidia-gpu。
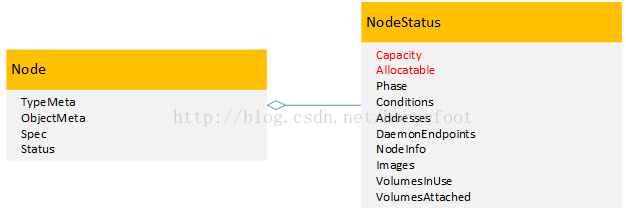
在启动kubelet的时候,通过增加参数--experimental-nvidia-gpu来将带有GPU的节点添加到kubernetes中进行管理。这个参数experimental-nvidia-gpu用来告诉kubelet这个节点中Nvidia品牌GPU的个数,如果为0表示没有Nvidia品牌GPU,如果不增加这个参数,那么系统默认为这个节点上没有Nvidia品牌GPU。
当节点上安装有多块Nvidia品牌GPU的时候,参数experimental-nvidia-gpu是可以输入大于1的数值的,但是对于kubernetes1.3这个版本,GPU还是个α特性,在代码中参数experimental-nvidia-gpu其实只支持两个值,分别是0和1,我们通过下面代码就可以看出来:
在运行Docker的时候,需要映射节点上的设备到docker中,这段代码是在告诉docker,只映射第一块Nvidia品牌GPU。通过上面代码可以看出来,在kubernetes1.3中,GPU这个α特性,参数experimental-nvidia-gpu其实只支持两个值,分别是0和1。通过上面代码也可以看出来,为什么在kubernetes1.3中只支持Nvidia品牌GPU,对于不同品牌的GPU,映射到Linux操作系统里面有着不同的设备路径,需要针对不同的GPU品牌分别进行实现。
(四) Kubernetes 1.6中支持GPU的实现
在kubernetes1.6中更全面的提供了对Nvidia品牌GPU的支持,保留了kubernetes1.3中针对Nvidia品牌GPU的α特性:alpha.kubernetes.io/nvidia-gpu,但是在启动kubelet的时候,去掉了参数--experimental-nvidia-gpu,改成了通过配置Accelerators为true来启动这个α特性,完整的启动参数是--feature-gates="Accelerators=true"。
在kubernetes1.3中只能利用节点上的一颗NvidiaGPU,但是在kubernetes1.6中会自动识别节点上的所有Nvidia GPU,并进行调度。

从上面代码中就可以看出来,在1.6中可以获取节点中所有NvidiaGPU设备。
下面是1.6中在kubelet中增加的Nvidia GPU相关结构体:
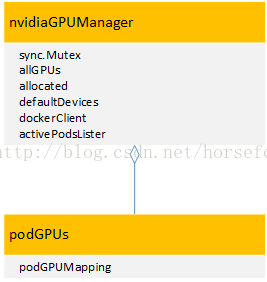
在nvidiaGPUManager这个结构体中,allGPUs变量表示这个节点上所有的GPU信息;allocated变量表示这个节点上已经被分配使用的GPU信息,这个allocated变量是一个podGPUs结构体变量,用来表示POD同已使用GPU的对应关系;dockerClient变量是docker接口变量,用来表示所有使用GPU的docker;activePodsLister变量表示这个节点上所有活动状态的POD,通过这个变量,可以释放已经处于终止状态POD所绑定的GPU资源。
在kubernetes中Nvidia GPU这个特性只是在容器是docker的时候才生效,如果容器使用的是rkt,是无法使用到Nvidia GPU的。
在1.6中可以参照下面样例使用Nvidia GPU:

可以看到,在1.6中使用GPU的时候,不同docker之间是无法共享GPU的,也就是说每个docker都会独占整个GPU,而且其实还需要kubernetes集群中所有节点上面的NvidiaGPU类型都是相同的,如果在一个集群中有的不同节点上面的Nvidia GPU类型不同,那么还需要给调度器配置节点标签和节点选择器,用来区分不同Nvidia GPU类型的节点。
在节点启动时,可以指明Nvidia GPU类型,并且作为节点标签传递给kubelet,如下所示:

在使用的时候,可以参考下面样例:

在这个样例中,利用到了节点亲和性规则,保证POD只能使用GPU类型是"TeslaK80"或"Tesla P100"的节点。
如果已经在节点上安装了CUDA(Compute UnifiedDevice Architecture,是显卡厂商NVIDIA推出的运算平台。 CUDA™是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。它包含了CUDA指令集架构以及GPU内部的并行计算引擎),那么POD可以通过hostPath卷插件来访问CUDA库:

(五) 未来展望
以后会逐渐完善这个α特性,让GPU成为kubernetes中原生计算资源的一部分,而且会提高使用GPU资源的方便性,还会让kubernetes自动确保使用GPU的应用可以达到最佳性能。
随着机器学习的火热,为了支撑各种以GPU为主的机器学习计算平台,相信kubernetes在GPU处理上还会继续快速完善,逐渐成为机器学习的底层编排架构。
原文地址:http://blog.csdn.net/horsefoot/article/details/68940665

开源、云原生的融合云平台
更多推荐
 0
0 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)